들어가며
플랫폼 스쿼드의 분기 목표는 결제 전환율 개선이었다. Mixpanel 퍼널을 들여다보던 중 카드 등록 단계에서 이탈이 눈에 띄게 컸다. 카드를 카메라로 비추면 번호가 자동으로 채워지는 스캐너를 직접 만들면 마찰이 줄지 않을까. 가설을 A/B 실험으로 먼저 검증하고, 결과가 좋으면 그대로 전체 배포하는 그림을 그렸다.
이 글은 그 v1을 만들어 띄우기까지의 기록이다. AVFoundation도 Vision도 처음 만지는 상태에서 카메라 프레임 한 장을 카드 번호 16자리로 바꿔내는 파이프라인을 한 편에 모았다. 같은 기능을 만들어야 하는 사람이 따라 읽으면, 어떤 카메라를 고르고 어떤 함정에서 크래시가 나고 어떤 결정이 정확도를 가르고 어디서 외부 OCR로 우회해야 하는지까지 그대로 가져갈 수 있게 썼다. 정확도 끌어올리기와 개선 사이클은 다음 편 — 정확도 끌어올리기에서 다룬다.
카메라 센서·ISP·코덱 같은 저수준 이론은 본문에서 가능한 한 가지치기하고, 이 한 편의 흐름은 "v1을 띄우려면 무엇을 결정해야 했나"에 맞췄다. 이론까지 따라가고 싶은 독자를 위해 두 편을 따로 두었다.
- ISP와 YCbCr — 카메라 프레임이 픽셀이 되기까지: Bayer RAW, 크로마 서브샘플, NV12 메모리 레이아웃
- YCbCr이 H.264 압축에 맞는 이유: 비압축 비용, I/P/B, NALU 비트스트림
이 화면이 동작하려면


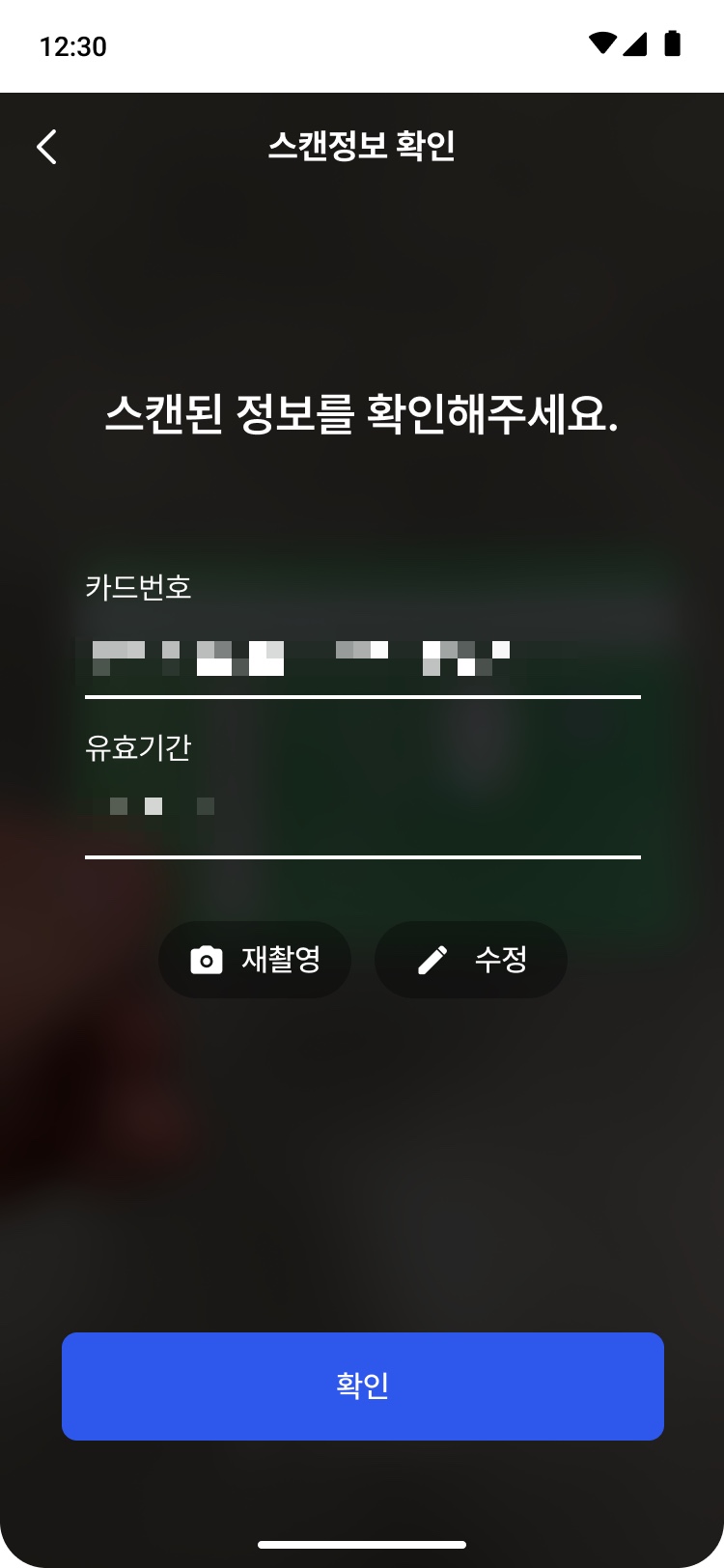
진입 → 인식 → 확인 (좌측부터)
화면 자체는 단순하다. 그런데 이 화면이 동작하려면 백그라운드에서 다섯 가지가 동시에 돌아가야 한다.
카드 가이드 안에 카메라 프리뷰가 실시간으로 떠 있고, 매 프레임 ROI를 잘라 OCR로 카드 번호를 추출한다. 인식이 끝나면 가이드 테두리가 파란색으로 바뀌면서 사용자가 셔터를 누르지 않아도 세션이 멈추고, 추출된 번호와 유효기간이 확인 화면으로 넘어간다. 저조도 환경을 위한 토치는 우상단 토글로 켜고 끄는데, 모든 기기·모든 순간에 켜지지는 않는다. 하드웨어 보유 여부와 현재 사용 가능 여부를 따로 본다.
화면 하단의 "직접 입력하기"는 fallback이다. OCR이 실패하거나 사용자가 카메라를 쓰지 않고 싶을 때 곧장 수동 입력 폼으로 넘어가는 길이다.
이 다섯 가지를 차례로 풀어 간다. AVCaptureDevice로 카메라를 고르고, AVCaptureSession에 묶고, 콜백으로 흘러나오는 CMSampleBuffer 프레임을 VideoToolbox로 Vision이 받을 수 있는 모양으로 바꾼다.
카메라에서 영상은 어떻게 받을까
카메라에서 들어온 한 프레임은 두 갈래로 갈라진다. 사용자가 보는 프리뷰 화면, 그리고 OCR이 번호를 뽑는 처리 경로. 둘 다 같은 세션에서 흘러나오므로 카메라 인스턴스를 따로 띄울 필요가 없다.
여기까지는 한 줄 설명이지만, 실제로는 카메라를 고르고, 세션에 묶고, 콜백으로 들어오는 프레임을 받고, Vision이 받을 수 있는 포맷으로 바꾸는 네 단계가 들어간다. 그 모든 단계가 iOS의 어떤 프레임워크와 어떤 데이터 타입을 거치는지 한번 펼쳐 두면 이후의 결정이 한결 빨라진다.
iOS 미디어 프레임워크 지형
어떤 카메라를 고를까
iPhone 후면 카메라 모듈은 셋이지만 카드 스캔에 맞는 건 메인 Wide 하나다. 울트라 와이드는 화각이 너무 넓어 카드 숫자가 작게 잡히고, 5× 망원은 최소 초점 거리가 길어 가까이 댄 카드에 초점 자체가 잡히지 않는다. AVCaptureDevice.default(for: .video)가 메인 Wide를 돌려주니 별도 지정도 필요 없다.
같은 AVCaptureDevice가 토치도 제어하는데, 여기서 한 번 크래시를 봤다. 처음에는 hasTorch만 확인하고 setTorchModeOn을 호출했는데 실기기에서 죽었다. hasTorch와 isTorchAvailable은 다른 값이다.
hasTorch → 이 기기가 토치 하드웨어를 갖고 있는가
isTorchAvailable → 지금 이 순간 토치를 켤 수 있는가
기기가 과열되면 iOS가 온도 보호 모드로 들어가 토치를 비활성화하고, 다른 앱이 카메라를 점유하거나 특정 카메라 구성이 토치를 지원하지 않을 때도 hasTorch는 그대로 true인 채로 isTorchAvailable만 떨어진다. 두 조건을 모두 확인한 뒤 켠다.
토치 설정도 반드시 lockForConfiguration() / unlockForConfiguration() 블록 안에서 호출한다. 락 없이 부르면 런타임 예외가 그대로 던져져서 앱이 죽는다.
세션을 묶는다
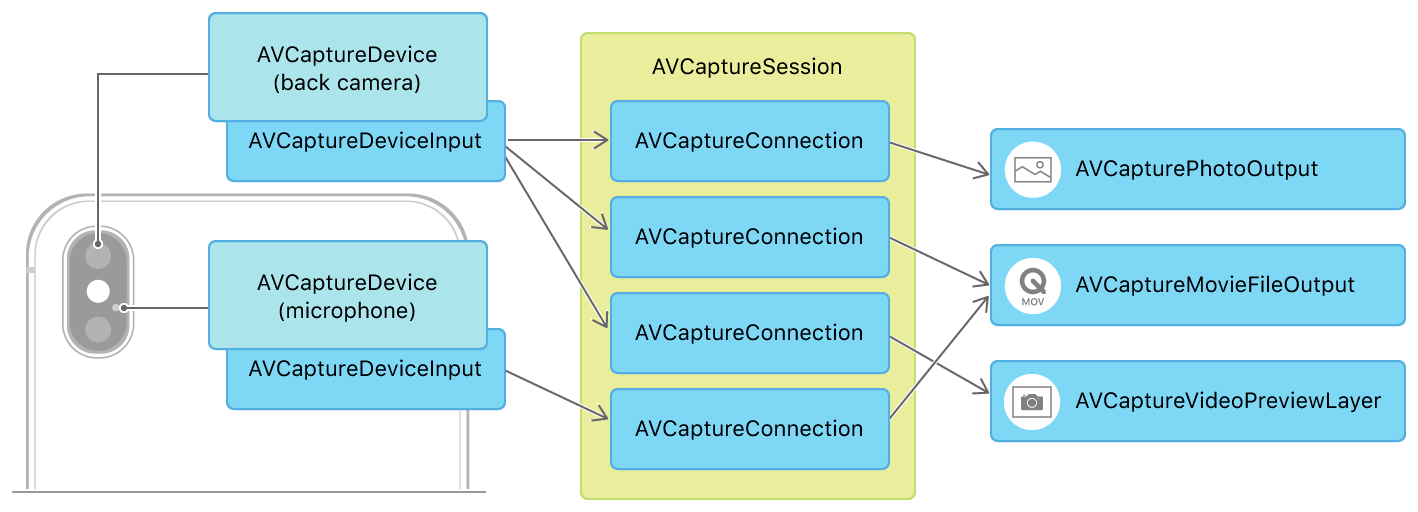
AVCaptureSession은 Apple 미디어 캡처의 허리다. 입력(카메라·마이크)과 출력(사진·영상·프리뷰)을 묶고, 디바이스 점유와 데이터 흐름을 관리한다. 위 그림은 표준 구성이고, 카드 스캐너에서는 카메라 입력 하나에 출력만 둘로 분기한다. 화면에 보여주는 AVCaptureVideoPreviewLayer, OCR로 흘려 보내는 AVCaptureVideoDataOutput. 한 세션 안에서 두 출력이 동시에 동작하므로 카메라 인스턴스를 따로 만들 일은 없다.
관여하는 클래스를 한 번에 그려 두면 이렇다.
AVCaptureDevice가 하드웨어, AVCaptureSession이 파이프라인을 잡고, AVCaptureVideoDataOutput이 프레임을 토해내는 출구, 델리게이트 콜백이 프레임마다 호출되는 진입점이다.
세션 큐와 버퍼 큐를 분리하는 이유
startRunning()과 stopRunning()은 블로킹 호출이라 한번 부르면 그 큐가 수백ms 동안 묶인다.
한 큐에서 세션 제어와 프레임 수신을 같이 처리하면, 세션이 시작·종료되는 수백ms 동안 프레임 콜백이 통째로 막혀 화면이 멈춘 듯 보인다. sessionQueue와 bufferQueue를 분리하면 라이프사이클 관리가 프레임 처리를 막지 않는다.
NOTE:
beginConfiguration/commitConfiguration은 카메라 전환, HDR 토글 같은 런타임 재구성에서만 쓴다. 초기 세션 설정에서 쓰면stop()이 configuration 구간에 호출될 때 크래시가 난다.
그 외 세션 옵션 두 가지
alwaysDiscardsLateVideoFrames = true. 카드 스캐너는 "지금 이 순간의 프레임"이 중요하다. bufferQueue가 바쁠 때 들어오는 새 프레임은 큐에 쌓지 않고 버린다. 1초 전 프레임에서 번호를 읽어내봐야 사용자는 이미 카드를 다른 각도로 들고 있다.
sessionPreset = .photo. .high(1920×1080)와 .photo(4032×3024) 사이에서 OCR 정확도를 실측해보면 차이가 분명하다. 카드 숫자는 작고, 카드를 멀리 대거나 살짝 기울이면 저해상도에서 인식률이 눈에 띄게 떨어진다. 처리 비용은 뒤의 ROI 크롭과 스로틀에서 잡으니 입력 단계에서는 픽셀을 충분히 깔아 둔다.
프레임 한 장의 안쪽: CMSampleBuffer · CVPixelBuffer · IOSurface
세션이 돌기 시작하면 델리게이트의 captureOutput(_:didOutput:from:)이 매 프레임 호출되고, 인자로 들어오는 게 CMSampleBuffer다. 시간 정보와 포맷 메타데이터를 함께 담은 미디어 컨테이너인데, 안에 어떤 페이로드를 담느냐에 따라 두 갈래로 갈린다.
카메라 라이브 프레임 경로에서는 항상 비압축 쪽, 즉 CVPixelBuffer가 들어온다. 인코딩된 영상을 디코딩하거나 네트워크 스트림을 받는 경로가 아니라 CMBlockBuffer는 카드 스캐너에서는 만질 일이 없다.
CVPixelBufferGetPixelFormatType을 찍어 보면 카메라가 어떤 포맷으로 프레임을 넘기는지 보인다.
kCVPixelFormatType_420YpCbCr8BiPlanarFullRange
YCbCr 4:2:0, NV12 메모리 레이아웃, Y 채널 0–255 FullRange. 즉 받은 채로는 Vision에 못 넣고, BGRA로 한 번 변환을 거쳐야 한다. 그 변환은 다음 절에서 다룬다.
그 전에 CVPixelBuffer가 단순한 바이트 배열이 아니라는 점만 짚어 둔다. 안쪽은 IOSurface 위에 올라가 있고, IOSurface는 CPU·GPU·Media Engine이 같은 물리 메모리를 포인터로 공유하는 메커니즘이다.
초당 30~60프레임이 각각 수십 MB. 이걸 매번 복사한다면 메모리 대역폭부터 무너진다. IOSurface 덕분에 같은 프레임을 프리뷰 레이어, OCR 처리 경로, VideoToolbox에 동시에 흘려 보내도 실제 픽셀 데이터는 한 자리에 그대로 있다. 카드 스캐너 파이프라인이 한 카메라 입력으로 여러 출력을 가질 수 있는 건 이 구조 위에서다.
CGImage로 바꾸기: VideoToolbox
남은 한 단계는 CVPixelBuffer(YCbCr 4:2:0)에서 CGImage(BGRA 32비트)로 가는 변환이다. Vision이 받을 수 있는 형태로 맞추는 일.
직접 짜는 선택지는 빠르게 접었다. YCbCr→RGB는 픽셀마다 색공간 행렬 곱이 들어가고, .photo 프리셋 4032×3024 해상도에서 30fps면 초당 약 3.7억 회 연산이 된다. CPU로 돌리면 배터리가 그대로 녹는다.
대신 iOS가 제공하는 게 VideoToolbox다. Apple Silicon의 전용 미디어 처리 유닛인 Media Engine으로 무거운 비디오 작업을 떨궈 주는 저수준 프레임워크인데, 인코딩·디코딩·포맷 변환의 세 갈래가 한 묶음으로 묶여 있다.
세 갈래 중 카드 스캐너에서 쓰는 건 가장 아래쪽 VTCreateCGImageFromCVPixelBuffer 한 줄이다. 인코딩(파일·네트워크로 내보내기)도, 디코딩(외부 비트스트림 받아오기)도 카메라 라이브 프레임 OCR에는 쓸 일이 없다. 우리는 카메라가 이미 풀어 넘긴 픽셀을 Vision이 받을 수 있는 모양으로만 바꾸면 된다.
VTCreateCGImageFromCVPixelBuffer(imageBuffer, options: nil, imageOut: &cgImage)이 한 줄 뒤에서 색공간 변환·메모리 레이아웃 정렬·픽셀 포맷 변환이 모두 일어난다. iOS 카메라가 기본 FullRange · BT.709로 떨어지므로, 옵션을 nil로 두면 메타데이터를 직접 손댈 일이 없다.
NOTE: Apple은
VTCreateCGImageFromCVPixelBuffer의 내부 경로(Media Engine / GPU / CPU 중 어디로 떨어지는지)를 명시하지 않는다. CPU 단독으로 떨어지는 케이스에서도 Accelerate(vImage)를 경유하므로, 직접 행렬 곱을 도는 것보다 훨씬 빠르다. 색공간 행렬, BT.709/BT.601 차이, FullRange/VideoRange 정규화, NV12 메모리 레이아웃 같은 이론은 ISP와 YCbCr — 카메라 프레임이 픽셀이 되기까지에 정리해 두었고, 코덱이 RGB가 아니라 YCbCr을 전제하는 이유는 YCbCr이 H.264 압축에 맞는 이유에 분리해 두었다.
한 장의 CGImage가 손에 들어오기까지
VTCreateCGImageFromCVPixelBuffer 한 줄이 짧아 보여도, 그 뒤에는 Bayer 패턴, ISP의 색 복원, YCbCr 색공간, IOSurface 공유 메모리, Media Engine 가속이 줄지어 서 있다. 카드 스캐너의 입력 단계는 이 한 줄로 정리되고, 결과물은 Vision이 그대로 받을 수 있는 CGImage 한 장이다.
다만 이 CGImage를 받자마자 OCR에 넘기면 처리 비용도, 정확도도 둘 다 무너진다. 다음 절은 같은 프레임을 그대로 흘리지 않고 "이 프레임은 읽을 가치가 있는가"를 먼저 묻는 게이팅 단계다.
분석 영역 잘라내기
손에 들어온 CGImage 전체를 OCR에 그대로 던지면 두 가지가 한꺼번에 무너진다. 카드 외 영역의 글자(상태바 시각, 안내 문구, 배경 무늬)가 인식 후보로 끼어들어 정확도가 떨어지고, 4032×3024 한 장을 매 프레임 풀어내자니 처리 비용이 감당이 안 된다. 그래서 OCR 직전에 두 가지 게이트를 끼운다. 카드 가이드 영역만 잘라내는 ROI 크롭, 그리고 호출 빈도를 제한하는 스로틀.
세 좌표계가 부딪힌다
처음에는 단순하게 생각했다. 화면에 그린 카드 가이드 오버레이의 frame을 그대로 CGImage.cropping(to:)에 넘기면 끝일 줄 알았다. 결과는 카드와 한참 떨어진 영역이 잘려 나왔다. 원인을 찾는 데 한참 걸렸는데, 결국은 카드 스캔 화면 위에서 세 좌표계가 동시에 굴러간다는 사실을 모르고 있었던 게 전부였다.
| 좌표계 | 원점 | 단위 | 비고 |
|---|---|---|---|
| UIKit 뷰 | 좌상단 | pt | 오버레이 frame.origin은 화면 좌상단 기준 |
| 카메라 이미지 | 좌상단 | px | 4032×3024, 1pt ≠ 1px (Retina에서 1pt = 2~3px) |
| Vision 정규화 | 좌하단 | 0~1 | 너비·높이를 1.0으로 정규화, y축이 뒤집힘 |
UIKit과 카메라 이미지는 원점이 같지만 단위와 크기가 다르다. UIKit과 Vision은 단위는 비슷하지만 y축 방향이 반대다. Vision으로 텍스트 박스를 받아 그대로 UIKit 뷰에 그렸을 때 카드 위쪽 글자가 화면 아래쪽에 그려지는 버그를 한 차례 만났는데, 정확히 이 y축 반전 때문이었다.
세 좌표계가 다른 원점·단위·크기를 쓰니, 오버레이의 CGRect 하나를 카메라 이미지 좌표로 옮기는 데도 보정이 들어간다.
종횡비가 셋 다 다르다
좌표계 보정이 단순한 비율 곱셈으로 끝나지 않는 이유는 종횡비 때문이다. 카드 스캔 한 화면 위에서 세 가지 비율이 동시에 살아 있다. 카메라 이미지는 전통적 사진 센서 비율인 4:3이고, iPhone 화면은 노치 이후 모델 기준 9:19.5 부근, 카드 가이드는 ISO/IEC 7810 ID-1 신용카드 표준(85.60 × 53.98 mm)에서 온 1.586:1이다.
AVCaptureVideoPreviewLayer는 기본 resizeAspectFill로 렌더링한다. 종횡비를 유지하면서 화면을 가득 채우되 넘치는 영역은 잘라낸다. 4:3 이미지를 9:19.5 화면에 채우면 좌우가 뷰 밖으로 흘러나가는 가로 오버플로(pillarbox)가 생긴다. 화면 정중앙에 그려진 오버레이를 카메라 이미지 좌표로 옮기려면, 뷰 밖으로 흘러나간 부분을 먼저 보정한다.
ROI를 이미지 좌표로 옮기는 함수
보정 자체는 두 단계다. 어느 방향으로 잘리는지 판단해서 scaleFactor와 visibleRect(이미지 좌표 기준, 실제로 뷰에 보이는 영역)를 구하고, 그 둘로 오버레이의 CGRect를 이미지 좌표로 옮긴다.
struct PreviewGeometry {
let viewSize: CGSize // 프리뷰 뷰의 크기 (UIKit pt)
let imageSize: CGSize // CGImage의 픽셀 크기
/// AVCaptureVideoPreviewLayer가 resizeAspectFill로 렌더링한다고 가정.
/// 뷰 좌표계의 ROI를 이미지 좌표계로 변환한다.
func roiInImage(_ roi: CGRect) -> CGRect {
let imageAspect = imageSize.width / imageSize.height
let viewAspect = viewSize.width / viewSize.height
let scale: CGFloat
let offset: CGPoint
if imageAspect > viewAspect {
// pillarbox: 이미지가 뷰보다 가로로 길다 → 높이 기준으로 스케일, 좌우 잘림
scale = imageSize.height / viewSize.height
let scaledImageWidth = imageSize.width / scale
offset = CGPoint(x: (scaledImageWidth - viewSize.width) / 2 * scale, y: 0)
} else {
// letterbox: 이미지가 뷰보다 세로로 길다 → 너비 기준으로 스케일, 상하 잘림
scale = imageSize.width / viewSize.width
let scaledImageHeight = imageSize.height / scale
offset = CGPoint(x: 0, y: (scaledImageHeight - viewSize.height) / 2 * scale)
}
return CGRect(
x: roi.origin.x * scale + offset.x,
y: roi.origin.y * scale + offset.y,
width: roi.width * scale,
height: roi.height * scale
)
}
}이 함수의 결과를 CGImage.cropping(to:)에 그대로 넘기면 카드 가이드 영역만 잘린 CGImage가 돌아온다. 다음은 이걸 OCR로 보내는 단계인데, 그 전에 한 단계가 더 있다.
OCR 호출을 두 게이트로 줄인다
ROI 크롭을 통과한 프레임을 매번 OCR에 던지면, 두 군데에서 동시에 무너진다.
VNRecognizeTextRequest 한 번이 수십수백ms 걸리는데 카메라는 33ms마다 새 프레임을 토해낸다. OCR이 한 장 처리하는 사이에 프레임이 310장씩 쌓이고, 이걸 큐에 넣어 두면 처리는 점점 밀려 결국 "사용자가 이미 치운 카드"의 과거 프레임을 인식하고 있게 된다. 또 카드를 가만히 들고 있는 동안 들어오는 연속 프레임은 사실상 같은 이미지인데, 매 프레임마다 OCR을 굴리면 외부 API를 끼웠을 때 비용도 같이 올라간다.
두 문제는 성격이 다르므로 가드도 따로 둔다.
isAnalyzing플래그: 현재 OCR이 돌고 있으면 새 프레임을 그냥 흘려 보낸다. 큐가 쌓이지 않는다.minInterval = 0.1s: 마지막 OCR 시작 시각에서 100ms가 지나지 않았으면 건너뛴다. 카메라가 30fps여도 OCR은 초당 10회로 묶인다.
두 조건이 독립적으로 동작하므로 결정 흐름은 다음 한 장으로 정리된다.
지금 바쁘냐(isAnalyzing)와 방금 했냐(스로틀)를 따로 묻는다. 둘 다 통과해야 OCR이 호출된다.
private var isAnalyzing = false
private var lastRunAt: Date = .distantPast
private let minInterval: TimeInterval = 0.1
func handle(_ frame: CGImage) async {
guard !isAnalyzing else { return } // 지금 바쁘냐
guard Date().timeIntervalSince(lastRunAt) >= minInterval else { return } // 방금 했냐
isAnalyzing = true
lastRunAt = Date()
defer { isAnalyzing = false }
await runOCR(on: frame)
}카드 번호 뽑아내기
ROI 크롭과 스로틀을 통과한 CGImage가 OCR 단계로 넘어온다. 처음에는 어렵지 않게 봤다. VNRecognizeTextRequest를 붙이고 결과에서 16자리 숫자를 정규식으로 뽑으면 끝일 줄 알았다. 실제로 그렇게 짜고 돌렸더니, 카드 번호 자리에 12/28이 들어왔다. 유효기간이었다. 정규식을 더 조여 봐도 이번에는 카드 배경 패턴이 우연히 16자리 숫자열로 잡혀 그대로 후보로 떨어졌다. 한참 들여다본 끝에 알게 된 건, 정규식 문제가 아니라 Vision이 돌려주는 텍스트 조각들의 구조 자체가 내가 예상한 것과 전혀 달랐다는 사실이었다.
문제를 풀려면 신용카드라는 물체가 OCR에 얼마나 적대적인지부터 짚고 가야 한다.
카드 OCR이 까다로운 이유
신용카드를 디자인하는 쪽의 목표는 "아름답고 위조하기 어려운 카드"이지 "OCR이 잘 읽는 카드"가 아니다. 그래서 디자인 결정 하나하나가 OCR 입장에서는 다 적이다.
번호가 양각으로 돋아 있는 엠보싱 카드는 비스듬한 조명에서 숫자 옆에 그림자가 생기고, Vision이 숫자와 그림자를 별개의 텍스트로 잡는다. 4 하나가 4 + d로 떨어지는 식이다. 표면의 UV 코팅과 홀로그램은 빛을 반사해 번호 일부를 과노출로 날려 버리거나 반사 패턴 자체를 텍스트로 오인하게 만든다. 카드사들이 배경에 깔아 두는 정교한 그라데이션과 마이크로 패턴도 마찬가지로 가짜 글자를 만들어낸다. 게다가 카드사들이 쓰는 폰트는 OCR 모델이 학습한 산세리프(Arial, Helvetica)가 아니라 OCR-B나 MICR 계열의 비표준 모노스페이스 폰트다. 0에 사선이 있거나 1의 세리프가 과장된 자형이라, 학습 데이터에 없는 폰트를 만나면 혼동이 뛴다.
요컨대 입력 단계에서 깨끗한 픽셀을 받는 것 자체가 어렵다. 그래서 OCR 호출은 단발 인식이 아니라 여러 프레임에서 후보를 모으고, 검증으로 골라내는 파이프라인으로 짜야 한다.
Vision으로 텍스트 뽑기
Vision의 텍스트 인식은 위치만 잡는 Detection과 위치+내용을 같이 잡는 Recognition 두 갈래로 갈린다.
카드 스캐너는 위치만 알아서는 할 수 있는 게 없으니 VNRecognizeTextRequest 한 갈래만 쓴다. Detection을 먼저 돌려 ROI를 좁힌 뒤 Recognition을 붙이는 2-pass 전략을 떠올렸지만, VNRecognizeTextRequest 자체가 내부적으로 Detection을 포함해서 두 번 나눠 도는 게 오히려 느렸다.
여기서 결정 두 개가 인식률을 가른다.
.fast가 아니라 .accurate
처음에는 .fast를 골랐다. 30fps 실시간 스트림에서 .accurate는 무겁다는 인상이 있었기 때문이다. 그런데 실측해 보니 .fast는 카드 번호 자형(엠보싱·OCR-B)에서 인식률이 너무 낮았다. 1을 l, 0을 O로 읽는 케이스가 반복됐고, 16자리 중 한 자리만 틀려도 그 프레임이 통째로 날아간다.
두 모드 차이는 단순한 "빠름/느림"이 아니라 뒤에서 도는 모델의 크기 자체가 다르다. .fast는 어휘와 자형 범위를 줄인 경량 모델이고, .accurate는 더 많은 파라미터와 폰트를 학습한 모델이다. 결국 .accurate로 올리고 호출 빈도는 앞서 게이팅으로 막는 방향으로 갔다. 게이팅이 흐린 프레임을 미리 거르므로 .accurate로도 처리량은 충분하다.
let request = VNRecognizeTextRequest()
request.recognitionLevel = .accurate.fast로 먼저 뽑고 실패하면 .accurate로 재시도하는 fallback 패턴도 있는데, 이미 게이팅이 흐린 프레임을 걸러내고 있으니 처음부터 .accurate 한 번 도는 게 누적 시간으로 더 짧다.
usesLanguageCorrection은 반드시 끈다
기본값(true)이면 Vision이 인식 결과를 자연어 단어에 가깝게 후처리한다. 카드 번호 4111을 보고 자연어 모델은 "단어가 아닌데"라고 판단해서 비슷한 알파벳 시퀀스(fill, pill, atll)로 교정해 버린다. 처음에 이걸 켜 둔 채로 돌렸다가 인식 결과에 뜬금없는 영단어가 섞여 나오는 원인을 한참 찾았다.
request.usesLanguageCorrection = falseVision 좌표를 화면 좌표로 옮긴다
인식 결과의 boundingBox를 그대로 UIKit 뷰에 그려서 디버그 오버레이를 띄워 봤더니, 카드 상단의 번호가 화면 하단에 그려졌다. 좌표 계산 버그가 아니라 두 프레임워크의 좌표계 원점이 달라서 생긴 결과다. Vision은 정규화 좌표 + Core Graphics 방식(좌하단 원점), UIKit은 좌상단 원점. boundingBox.origin.y = 0.8이 Vision에선 이미지 상단 가까이지만 UIKit으로 옮기면 화면 하단으로 떨어진다. 분석 영역 절에서 다룬 좌표계 충돌과 같은 축 뒤집기다.
NOTE:
VNImageRequestHandler에CGImagePropertyOrientation을 정확히 넘기지 않으면 좌표 변환을 잘 해도 여전히 어긋난다.AVCaptureSession에서 나오는 프레임은 대부분.rightorientation이므로, 이 값을 핸들러에 같이 넘겨야 회전을 고려한boundingBox가 돌아온다.
// Vision boundingBox → UIKit CGRect
func convertToUIKitRect(_ boundingBox: CGRect, imageSize: CGSize) -> CGRect {
let x = boundingBox.origin.x * imageSize.width
let y = (1 - boundingBox.origin.y - boundingBox.height) * imageSize.height
let w = boundingBox.width * imageSize.width
let h = boundingBox.height * imageSize.height
return CGRect(x: x, y: y, width: w, height: h)
}흩어진 조각에서 16자리를 조립한다
Vision이 돌려주는 [VNRecognizedTextObservation]은 카드에 인쇄된 모든 텍스트 조각의 배열이다. 같은 카드 번호 4111 1111 1111 1111이 프레임마다 다른 모양으로 떨어진다.
["4111", "1111", "1111", "1111"] // 4그룹 분리 (일반적)
["4111 1111", "1111 1111"] // 2그룹 분리
["4111", "11", "11", "1111", "1111"] // 더 잘게 쪼개짐
["4111111111111111"] // 붙어서 한 덩어리
여기에 유효기간 12/28이나 카드사 영문명, 카드 소지자 이름이 같은 배열에 섞여 나온다. 정규식 하나로 골라낼 수 없으니 줄을 복원하고, 그 줄에서 카드 번호 자리를 식별하는 두 단계로 푼다.
줄 복원의 단서는 Y좌표다. 카드 번호 한 행은 인쇄 높이가 같으니 boundingBox.midY가 거의 일치한다. Y tolerance를 이미지 높이의 0.05로 잡으면 한 줄로 잘 묶이고, 같은 줄에 묶인 조각들은 X좌표 오름차순으로 정렬해서 왼쪽부터 이어 붙인다. Vision은 같은 줄 안에서 순서를 보장하지 않으므로 정렬은 필수다. tolerance가 너무 좁으면 한 줄이 둘로 쪼개지고, 너무 넓으면 카드 번호 줄과 유효기간 줄이 한 줄로 붙어 버린다. 카드가 살짝 기울어 있으면 이 값을 0.05보다 넓히거나 회전 보정을 한 번 거쳐야 한다.
줄을 복원해도 OCR은 여전히 자형 혼동을 낸다. 카드 번호 자리에는 숫자만 들어가야 하지만, 알파벳이 섞여 들어오는 경우가 흔하다.
| 실제 | OCR 오인식 후보 | 이유 |
|---|---|---|
1 | l, I, | | 세로 획 하나, 폭이 좁음 |
0 | O, o, Q | 타원형, 내부가 빈 모양 |
8 | B | 좌우 대칭, 세로로 두 원 |
6 | G, b | 상단 개방 곡선 |
5 | S | S자 형태 공유 |
카드 번호 자리에 한해서는 l/I→1, O→0 같은 매핑을 강제로 적용한다. 단, 이 매핑은 카드 번호 자리에서만 켠다. 카드 소지자 이름 자리에 똑같은 매핑을 걸면 진짜 알파벳이 다 숫자로 바뀌어 버린다.
v1은 여기까지로 출하했다. 즉 조립된 16자리 후보를 그대로 사용자 확인 화면에 띄우고, 실제 결제 등록은 사용자가 한 번 검토한 뒤 진행하도록 했다. 배경 패턴이 우연히 토해낸 가짜 숫자열이 후보로 떨어지는 경우가 분명히 있었지만, 사용자의 시각 검증을 마지막 가드로 두고 일단 배포한 셈이다. 이 빈틈을 출력 단의 자동 검증으로 메우는 작업, 즉 Luhn 체크섬과 BIN(카드 번호 앞 6~8자리로 발행 기관을 식별하는 표준) 검증을 출력 단에 얹는 일은 다음 편에서 다룬다.
Vision이 못 풀면 CLOVA로 우회한다
처음 설계는 온디바이스 Vision만으로 끝까지 가는 그림이었다. 외부 OCR을 끼우는 순간 라이선스, 호출 비용, 무엇보다 카드 이미지의 외부 전송이라는 보안 무게가 같이 들어오기 때문이다.
그런데 사내 카드 표본으로 실측해 보니 Vision이 구조적으로 약한 케이스가 분명히 보였다. 비표준 폰트의 프리미엄·금속 카드, 아랍어·태국어·키릴 문자 같은 비라틴 문자가 함께 인쇄된 해외 카드, 직사광선 아래 야외 환경. 이런 조건에서는 게이팅으로 입력 품질을 올려도 메꿔지지 않았다. 결제 등록 실패가 그대로 늘어나는 신호라 방치할 수 없어, 이 케이스에 한해서만 Naver CLOVA OCR로 우회하는 fallback을 한 갈래 더 두기로 했다. v1에 들어간 외부 의존성은 이 한 갈래가 전부다.
NOTE: iOS 16+의
VNRecognizeTextRequest는recognitionLanguages를 명시하지 않으면 기기 언어 설정에 따라 모델이 달라진다. 한국 출시 앱이라면["ko-KR", "en-US"]를 명시해 두는 편이 안정적이다.
서버사이드 OCR이 가지는 강점은 단순하다. 폰에 들어갈 필요가 없으니 모델 크기에 제약이 없고, 더 다양한 폰트·언어로 학습된 큰 모델을 그대로 굴릴 수 있다. CLOVA OCR이 쓰는 모델은 수억 장의 이미지로 학습되어 있다. 다만 그 강점에는 세 가지 비용이 따라붙는다. 네트워크 레이턴시(빠른 환경에서도 왕복 200~500ms), 카드 이미지를 서버로 보낸다는 보안 노출, 그리고 호출 단위 과금. 이걸 매 프레임 굴릴 수는 없다.
그래서 fallback은 항시 호출이 아니라 Vision이 같은 카드에서 N회 연속 실패할 때만 트리거되도록 가드를 한 겹 두었다. Vision이 잘 푸는 카드에서는 서버 호출 자체가 일어나지 않고, Vision이 막힐 때만 서버가 한 번 도와준다. 이미지 외부 전송에 대해서도 사용자 동의 플로우와 무저장 정책을 같이 넣었다.
v1 시점에는 fallback 호출 비율이 의도보다 비싸게 잡혔다. 입력 단계 게이팅이 아직 들어가지 않아서 Vision 실패 빈도 자체가 높았기 때문이다. Laplacian 분산 기반 흐림도 게이팅을 입력 단에 붙여 fallback 호출을 끌어내리는 작업은 다음 편에서 다룬다.
A/B 실험으로 효과 검증
스캐너를 전면 배포로 가져가기 전에 PM과 합의한 가드는 하나였다. A/B로 실제 전환율 개선이 확인되어야 푼다. Remote Config로 실험 키를 만들고 카드 등록 화면 진입 시점에 두 그룹으로 분기했다.
- A(기존): 수동 입력 폼
- B: 카드 스캐너 선진입 + 수동 입력 fallback
B 그룹은 화면이 열리자마자 스캐너가 먼저 뜨고, 인식에 성공하면 번호가 폼에 자동으로 채워진다. 실패하거나 사용자가 직접 입력을 원하면 한 탭으로 폼으로 돌아간다. 두 그룹 모두 카드 등록 화면 진입과 등록 완료를 같은 기준으로 추적해 비교했다.
2025년 2월 중순부터 4월 초까지 약 7주간 실험을 굴렸고, 각 그룹 수천 건 이상의 코호트를 기준으로 Hackle 대시보드에서 통계적 유의성(p < 0.05)을 확인했다.
| 지표 | A(기존) | B |
|---|---|---|
| 카드 등록 전환율 | 38.29% | 73.33% |
| 구매 완료 전환율 | 72.39% | 75.32% |
카드 등록 전환율이 38%에서 73%로 약 35pp 올랐고, 그 뒤 단계인 구매 완료 전환율은 2.93pp 올랐다. 스캐너의 혜택을 받는 대상은 카드가 등록되지 않은 상태로 결제를 시도한 유저인데, 이 유저군은 월 수만 건 규모의 전체 결제 퍼널에서 8~9%를 차지한다. 즉 등록 화면 내부의 35pp 개선은 전체 퍼널에서는 약 3pp 수준의 임팩트로 전달된다.
결과를 팀에 공유하고 B 그룹 전체 배포를 확정했다. 분모와 효과 크기가 명확했던 만큼 배포 결정에는 이견이 없었다.
남은 문제와 다음 단계
A/B 결과가 좋아 배포는 했지만, 운영을 시작하자마자 두 가지 한계가 함께 보였다.
첫째는 인식 정확도 자체의 출렁임이다. 광택이 강하거나 손가락이 일부를 가린 카드, 손이 흔들린 프레임에서 잘못된 16자리가 폼에 채워지는 경우가 반복됐다. 잘못 채워진 번호로 등록을 시도하면 서버에서 오류가 떨어지고 사용자는 결국 수동으로 다시 입력하게 된다. 스캐너가 단계를 줄여 주지 못하고 한 단계를 더 만들어 버리는 결과다.
둘째는 개선 사이클 자체가 느렸다는 점이다. 알고리즘을 한 줄 바꿔 보려 해도 실기기에 빌드를 올리고, 카메라와 실제 카드, 다양한 조명 조건을 매번 새로 세팅해야 인식률을 확인할 수 있었다. 어떤 카드의 어떤 프레임에서 왜 실패했는지 재현하기도 어렵다.
두 문제는 사실 같은 한 문제였다. 정확도를 올리려면 빠르게 시도하고 빠르게 측정해야 하는데, 카메라에 의존한 검증 루프가 그 사이클을 막고 있었다. 다음 편에서는 카메라 없이 파이프라인을 돌릴 수 있는 구조를 먼저 만들고, 그 위에서 Laplacian 게이팅과 BIN 검증을 붙여 인식 정확도와 등록 완료까지 걸리는 시간(TTC)을 함께 끌어내린 과정을 다룬다.
참고 자료
- Apple: AVCam — Building a Camera App
- Apple: VideoToolbox Framework
- Apple: CVPixelBuffer
- Apple: IOSurface Framework
- Apple: CMSampleBuffer
- Apple: AVCaptureSession
- Apple: A17 Pro — Apple Silicon
- Apple: Accelerate — vImage
- Apple: vDSP
- Apple: VNRecognizeTextRequest
- Apple: VNRecognizedTextObservation
- Apple: Recognizing Text in Images
- ITU-R BT.709 — Parameter values for the HDTV standards
- Tmap Mobility — Vision API를 통한 카드번호 인식 OCR 개발
- Wikipedia: Chroma subsampling
- Wikipedia: Bayer filter